Keeleminutid. Mida näitab tehisaru baromeeter?
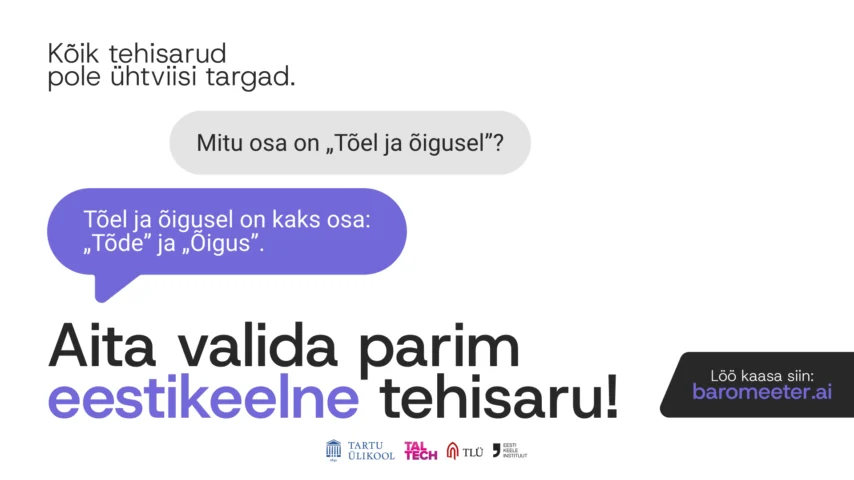
Kes elab tegelikult Vargamäel? Milliseid vaatamisväärsuseid võiks külastada Lõuna-Eestis? Millise rahvuskangelase nime kannab üks Eesti kaitseväe pataljonidest? Need on küsimused, millele tänased suured keelemudelid peaksid oskama vastata, aga paraku kipuvad nad just selliste teemadega hätta jääma, kirjutab EKI keeletehnoloog Silver Vapper.
Kui vaatame suurte keelemudelite treeningandmeid, moodustab eestikeelne sisu neist alla 0,01 protsendi. See tähendab, et isegi kõige võimekamad mudelid teavad meie keelest ja kultuurist pigem üsna vähe. Keeletehnoloogia vaatenurgast on probleeme vähemalt kaks. Esiteks puuduvad mudelitel piisavad eestikeelsed eeltreeningandmed, aga veelgi olulisem on, et neil puudub peenhäälestatus just meie keeleruumi jaoks. See on protsess, kus mudelile õpetatakse inimeste eelistusi ehk näiteks milline vastus on parem, mis stiilis teksti kirjutada või milliseid fakte esile tõsta. Praegu tehakse seda peamiselt inglise keeles ja ameerikaliku kultuuritausta põhjal.
Just selle lünga täitmiseks lõi kamp Eesti teadlasi tehisaru baromeetri, millega kogutakse andmeid selle kohta, milliseid vastuseid kasutajad eelistavad. Need on andmed, mis tekivad, kui kasutaja sisestab viiba (teisisõnu prompt’i), kaks mudelit vastavad sellele oma võimekuse piires ning seejärel kasutaja valib neist parema.
Baromeetris on praegu üle kolmekümne mudeli, sealhulgas näiteks GPT, Claude, Gemini ja Llama erinevad versioonid, aga ka väiksemad avatud lähtekoodiga mudelid. Teadlase jaoks on põnev võrrelda, kuidas erinevad arhitektuurid ja treeningmetoodikad mõjutavad eesti keele mõistmist. Näiteks võib täheldada, et mõned mudelid saavad paremini aru keerulisest lauseehitust teised jälle tunnevad paremini kultuurispetsiifilisi viiteid. Et aga taolisi uuringuid läbi viia, on jällegi vaja hulganisti andmestikke, mille alusel mudeleid neis aspektides võrrelda.
Andmete kvaliteedi ja hindamismetoodika objektiivsuse tagamiseks on oluline, et baromeetri kasutajad esitaksid võimalikult mitmekesiseid küsimusi, alates tehnilistest probleemidest kuni loovate ülesanneteni. Eriti väärtuslikud on küsimused, mis nõuavad kohalikku teadmist või kultuuriruumi taju. Need aitavad välja tuua mudeli nõrku kohti just seal, kus ingliskeelne eeltreening ei aita.
Projekti eesmärk on koguda vähemalt 50 000 võrdlust. Kvalitatiivsete eelistusandmete puhul on see piisav hulk, et alustada tõsisemalt peenhäälestusprotsessiga. Kogutud andmestik muutub avalikuks ressursiks, mida saavad kasutada kõik, kes soovivad arendada paremaid eestikeelseid keelemudeleid.
Tehisaru valdkond areneb meeletu kiirusega ning juba sügisel jõuavad esimesed ametlikud lahendused TI-hüppe raames ka Eesti koolidesse. Olgugi, et baromeetris kajastuvad tulemused sealsete lahenduste valimisel enam rolli ei jõua mängida, siis on selle raames kogunev andmestik ikkagi väga väärtuslik tugitala. Seda saavad ära kasutada kõik järgnevad projektid, asutused või ka lihtsalt huvilised, kui nad soovivad valida parimat mudelit just eesti keele ja kultuuriruumi eripäradest lähtudes. Seetõttu on iga hinnang baromeetris küll väike, aga oluline samm parema digitaalse eesti keele suunas.
Kirjuta nutikaid prompt‘e ning pane oma lemmikmudelid proovile!
Tehisaru baromeetri on välja töötanud Tartu Ülikooli kaasprofessor Kairit Sirts, nooremteadurid Hele-Andra Kuulmets ja Aleksei Dorkin ning Tallinna Ülikooli külalislektor Krister Kuusmaa.
Lugu ilmus 09.06.2025 ERR-i kultuuriportaalis.
